
Big data

L’État a accéléré sa mise en place pendant l’épidémie : le Health Data Hub, ou plateforme des données de santé, doit regrouper un très large éventail de données sur les soins, l’assurance maladie, les pharmacies, les Ehpad… L’esprit du projet étant que l’intelligence artificielle fera avancer la médecine. Le géant Microsoft en est l’hébergeur.
Ce 11 mai, premier jour du début du déconfinement, dans les hôpitaux parisiens de l’AP-HP, le personnel soignant sort de deux mois très tendus. Au plus fort de la crise, début avril, plus de 2600 patients ont dû être placés en réanimation, dépassant largement les capacités hospitalières initiales. Une tâche supplémentaire est cependant assignée aux soignants : dans un courrier, des responsables de l’AP-HP enjoignent les soignants et chefs de service de bien s’assurer d’envoyer « de manière hebdomadaire » les données sur les patients Covid.
« Afin d’alimenter la plateforme des données de santé, le ministère de la Santé a décidé par un arrêté du 21 avril 2020 de mettre en place une remontée accélérée et simplifiée des données du programme de médicalisation des systèmes d’informations », précise ce même courrier. Ce dispositif existe depuis les années 1990, pour quantifier l’activité hospitalière. 30 ans plus tard, à l’âge des algorithmes et de l’intelligence artificielle, les données de santé semblent encore plus précieuses aux yeux du ministère. Le travail bureaucratique se rappelle, encore et toujours, au bon souvenir de celles et ceux qui ont été en première ligne.
L’État a donc publié un arrêté en pleine pandémie pour accélérer la mise en place d’un projet lancé en 2018 : le Health Data Hub, ou plateforme des données de santé. Au prétexte de la « gestion de l’urgence sanitaire », le gouvernement a ainsi décidé que cette plateforme pourrait dorénavant récolter un large éventail de données de santé, allant des diagnostics aux causes de décès : celles des hôpitaux, des maisons départementales du handicap, celles relatives aux soins dans les Ehpad, les « données de pharmacie » des médecins généralistes, celles « issues d’applications mobiles de santé et d’outils de télésuivi, télésurveillance ou télémédecine », les résultats d’analyses des laboratoires hospitaliers et de ville, et même des données du fichier d’identification des victimes normalement prévu pour des situations d’attentats mais déjà utilisé pour les gilets jaunes blessés suite à des manifestations [1]
Quand les données financées par la solidarité nationale doivent être partagées avec le privé
La nouvelle plateforme ratisse large. Une partie de ces données – celles des facturations de l’hôpital, des feuilles de soins de l’assurance maladie, des maisons départementales du handicap et des causes médicales des décès – sont déjà regroupées dans une base depuis 2016 [2]. L’objectif du hub est d’élargir les types de données récoltées, de regrouper des bases déjà existantes, de centraliser les démarches pour y avoir accès, et de permettre l’usage à grande échelle d’outils d’intelligence artificielle sur ce nouveau gisement de « big data ».

Un data center. CC 123net via Wikimedia Commons
En octobre 2018, une mission de préfiguration définit les contours d’un système national centralisé qui regrouperait l’ensemble des données de santé publiques. Celle-ci pointe la nécessité d’une plateforme centralisée, et affirme que « les données financées par la solidarité nationale doivent être partagées avec tous les acteurs, publics comme privés ».
La nouvelle loi santé de 2019 acte la création du hub. Il est effectif en décembre. Trois mois plus tard, l’épidémie de Covid se répand. L’arrêté d’avril sur la collecte de données ne vaut que pour la durée de l’état d’urgence sanitaire. Un nouvel arrêté doit déterminer quelles données continueront à alimenter ce hub après le 10 juillet. « L’idée, c’est que le catalogue des données puisse être évolutif, celui de 2020 ne sera sans doute pas celui de 2021 ou de 2025 », explique à Basta ! Stéphanie Combes, la directrice du Health Data Hub. Traduction : on ne sait pas exactement quelles seront les données regroupées sur le hub après l’été, dans un an ou dans cinq ans. Cela peut changer.
Des projets médicaux et des projets gestionnaires
À quoi et à qui serviront ces données sur notre système et notre état de santé ? Ceux qui voudront les exploiter devront déposer un dossier pour chaque utilisation de ces informations. Un comité instruit ces demandes, évalue leur pertinence scientifique, leur finalité et leur « caractère éthique », souligne Stéphanie Combes. Puis, les dossiers sont transmis à la Commission nationale de l’informatique et des libertés (Cnil). Il peut s’agir d’institutions publiques, d’hôpitaux, d’instituts de recherches, ou d’entreprises privées. Les assureurs peuvent ainsi y avoir accès. « Mais il y a des finalités interdites, comme démarcher les établissements de santé pour leur vendre des produits ou bien personnaliser la tarification des assurances », assure la directrice du hub. Jusqu’ici, les données ont été mises à disposition à titre gracieux. À terme, leur utilisation devrait être monnayée, en tous cas pour les entreprises. « La tarification n’existe pas encore mais elle pourra être mise en place dans le futur à destination des utilisateurs privés », nous précise Stéphanie Combes.
De nombreux projets ont déjà été validés par le comité scientifique et éthique de la plateforme et ont accès aux données. Un projet porté par des instituts de recherche publique vise ainsi à « prédire les trajectoires individuelles des patients parkinsoniens ». La mutuelle Malakoff Médéric a aussi pu avoir accès à des données pour « mesurer et comprendre les restes à charge réels des patients ». D’autres demandes sont déposées par des start-up de l’intelligence artificielle. Ainsi OPBI Santé, fondée par deux « consultants en organisation hospitalière », souhaite par exemple accéder aux données pour déterminer les durées de séjour qui seraient les plus efficientes pour chaque type de pathologie. « Des durées atteignables et pertinentes, mais nécessitant les meilleures pratiques organisationnelles », vante la start-up.
Une partie de ces projets a moins à voir avec le soin qu’avec la gestion des ressources, matérielles et humaines. Au Royaume-Uni, le service national de santé NHS s’est associé pendant l’épidémie au groupe états-unien d’intelligence artificielle Palantir (qui a travaillé avec la CIA), ainsi qu’avec Amazon, Google et Microsoft pour tenter, avec les data, de rendre plus efficace la gestion des ressources hospitalières, sans augmenter celles-ci.
Les États-Unis pourront-ils avoir accès aux données de santé de 67 millions de Français ?
En France, la plateforme s’est alliée à Microsoft : elle est hébergée sur le cloud Microsoft Azure. Le choix du géant informatique est le point qui a suscité le plus de contestations autour du nouveau hub. « Avec Microsoft comme hébergeur, on entre dans un autre territoire juridique, qui n’est pas celui de l’Europe, pas celui du règlement européen sur la protection des données [RGPD]. C’est stratosphérique ! » critique ainsi Adrien Parrot. Le jeune médecin s’est formé à l’informatique, à l’école 42, spécialisée dans la formation de développeurs, et a travaillé à l’entrepôt des données de santé de l’AP-HP. Celui-ci a adopté des outils de gestion des bases de données en open source [3]. Avec des ingénieurs, Adrien Parrot a créé le collectif InterHop. L’initiative veut promouvoir les alternatives permettant « d’éviter la collecte des données au sein des Gafam (Google, Apple, Facebook, Amazon, Microsoft) ou des BATX chinois (Baidu, Alibaba, Tencent, Xiaomi) ». Des alternatives « libres » existent donc.
Porteur d’une informatique du partage et du logiciel libre, InterHop voit évidemment d’un très mauvais œil le choix de la multinationale Microsoft pour héberger la plateforme centralisée des données de santé françaises. « Avec le Health Data Hub, d’un seul coup, c’est une base de données qui concerne l’ensemble de la population, l’ensemble des données de santé, tout ce qui est remboursé par la sécurité sociale. Et toutes ces données sont envoyées sur une plateforme qui ne dépend pas de notre juridiction », déplore Adrien Parrot.
Dans son avis d’avril dernier sur le hub, la Cnil s’est aussi inquiétée que « le contrat mentionne l’existence de transferts de données en dehors de l’Union européenne dans le cadre du fonctionnement courant de la plateforme, notamment pour les opérations de maintenance ou de résolution d’incident » [4]. Microsoft pourrait donc, selon la Cnil, envoyer des données de santé vers les États-Unis. Stéphanie Combes avait démenti cela dans Mediapart en mai : « Nous avons bien spécifié que les données ne devaient pas sortir du territoire français. »
Les craintes persistent. Car même si les données stockées par Microsoft ne sortent pas du territoire numérique national, les États-Unis ont adopté en 2018 une loi nommée Cloud Act qui permet à la justice états-unienne d’avoir accès aux données stockées par des entreprises US, qu’elles le soient sur le sol des États-Unis ou dans d’autres pays. Ce « raffinement ultime de l’extraterritorialité américaine », disait un rapport parlementaire l’an dernier, « permet aux autorités américaines de collecter les données d’entreprises cibles, où que celles-ci soient stockées dans le monde ». [5]. Soit, mais les données hébergées sont cryptées, ce qui pourrait rassurer… sauf que la Cnil a relevé que les clés de cryptage sont détenues par l’hébergeur Microsoft. Donc, celles-ci « seront conservées par l’hébergeur au sein d’un boîtier chiffrant, ce qui a pour conséquence de permettre techniquement à ce dernier d’accéder aux données ».
Des données « parmi les plus intimes, protégées de façon absolue par le secret médical »
D’autres acteurs s’opposent à ce hub. Ce 11 juin, le Conseil d’État examine un référé déposé par un groupes d’une quinzaine d’organisations : associations et éditeurs de logiciels libres, collectif InterHop, syndicats… Pour elles, le Health Data Hub « porte une atteinte grave et sûrement irréversible aux droits de 67 millions d’habitants de disposer de la protection de leur vie privée notamment celle de leurs données parmi les plus intimes, protégées de façon absolue par le secret médical : leurs données de santé ». [6].
Déjà en janvier, le Conseil national des barreaux avait mis en garde contre « les risques de violation du secret médical » lié au hub [7]. Un collectif d’entreprises du logiciel libre a aussi dénoncé la manière dont le marché a été attribué à Microsoft Azure : aucun appel d’offre n’a été organisé pour sélectionner Microsoft comme hébergeur [8]. Le marché a été attribué directement au géant états-unien sans que des hébergeurs européens ou français aient pu proposer une offre alternative. La directrice du hub s’en défend : le groupement d’intérêt public de la plateforme a choisi Microsoft sans marché public car il était alors le seul à offrir les services demandés. « Quand nous avons fait l’analyse des offres existantes, il n’y avait pas beaucoup d’options qui correspondaient à nos contraintes », répond Stéphanie Combes à Basta !. Dans un échange de tweets début juin, le fondateur de l’hébergeur français OVH (principal hébergeur français), Octave Klaba, a reconnu qu’à l’époque du lancement du hub, sa société n’avait pas toutes les fonctionnalités demandées.
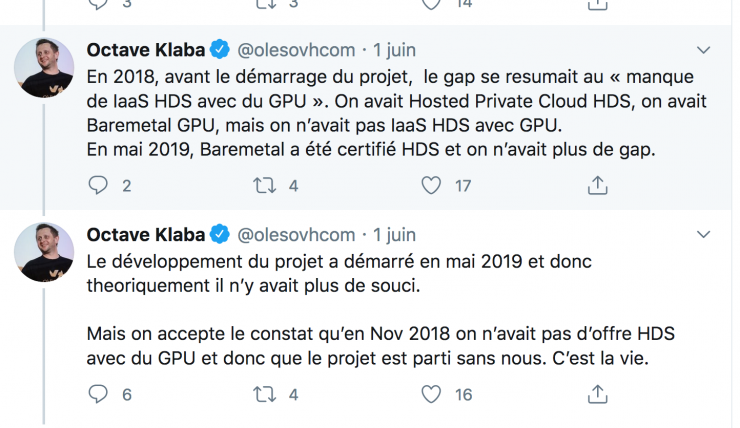
Adrien Parrot admet lui aussi qu’en 2018 les choix pouvaient être limités. Il ajoute que ce n’est plus le cas. « Aujourd’hui, il y un tas d’hébergeurs qui sont certifiés pour le niveau de sécurité nécessaire, plus seulement Microsoft. Au début, on nous disait que c’était seulement pour la phase de test. Soit. La phase de test est passée, on peut changer d’hébergeur. Il y a le cloud d’OVH, mais aussi Orange, il y en a plein… ». Le hub pourrait-il changer d’hébergeur, tourner le dos au Gafam et opter pour des solutions européennes ? Stéphanie Combes ne répond pas vraiment oui : « Nous devons faire l’analyse par rapport à nos exigences fonctionnelles, et comment les acteurs peuvent y répondre. Nous nous sommes engagés à mettre à jour nos analyses de réversibilité chaque année. Nous l’avons fait à l’automne 2019 et il y avait encore un écart entre les services dont on avait besoin et ceux qui étaient disponibles chez les acteurs français et européens. »
Pour produire des données de santé, il faut des soignants

Sur le terrain du soin, ces discussions de marché publics et de fonctionnalités informatiques peuvent sembler lointaines. Pourtant, pour produire des données de santé, il faut des soignants, qui « codent » et remplissent les formulaires numériques prévus par les logiciels. Fin 2019, des médecins hospitaliers avaient lancé, dans la foulée du large mouvement de grève des urgences, une grève du codage. Ils refusaient de produire les données sur les soins facturés.
En avril, des soignants des services de psychiatrie ont publié une enquête, fruit d’un an de travail, sur le poids du numérique et de la data dans les soins et leur travail. « Ces données vont aussi permettre de renforcer et d’accélérer le processus de marchandisation de la santé mentale », notamment « avec une multiplication des partenariats public/privés », analysent-ils [9]. Pour eux, « l’après coronavirus sera une lutte pour réaffirmer que rien ne peut remplacer “une présence en chair et en os” dans les métiers du soin comme partout ailleurs ». Comme un rappel au réel face aux incantations de l’intelligence artificielle.
Rachel Knaebel
Photo de une : © Anne Paq
Notes
[1] Voir cet article sur Mediapart.
[2] Dans le Système national des données de santé (SNDS).
[3] Voir le site de l’entrepôt des données de santé de l’AP-HP.
[4] Voir l’avis de la Cnilavis.
[5] Rapport de Raphaël Gauvin, 2019.
[6] Voir l’article de Mediapart.
[7] Voir le communiqué.
Commentaires récents